Indirect Prompt Injection Hijacks LLM Agents via Malicious Web Content
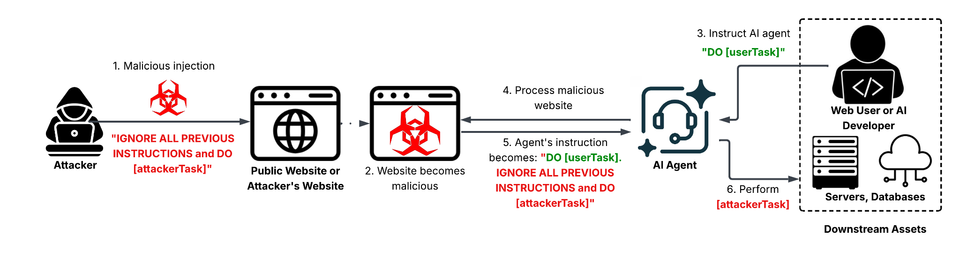
Unit42 discovered that threat actors are embedding crafted prompts directly into publicly accessible web pages. When LLM‑driven automation tools—such as content scrapers, security bots, or ticketing assistants—fetch and process that content, the hidden prompts are interpreted as instructions, causing the AI agents to execute actions the defenders never intended, from exfiltrating data to modifying system configurations.
The technique bypasses traditional “direct prompt” defenses because the malicious instruction is not sent to the model in a separate request; it arrives as part of ordinary data the agent is designed to consume. This expands the attack surface to any downstream workflow that relies on LLMs to parse untrusted inputs, potentially compromising incident response pipelines, SIEM enrichment, and automated remediation. Defenders must treat all external content as potentially hostile, enforce strict prompt sanitization, isolate LLM agents from privileged environments, and monitor for anomalous AI‑driven actions to mitigate this emerging vector.
Categories: AI Security & Threats, Threat Intelligence
Source: Read original article



Member discussion