
Indirect Prompt Injection Hijacks AI Agents via Web UI Manipulation
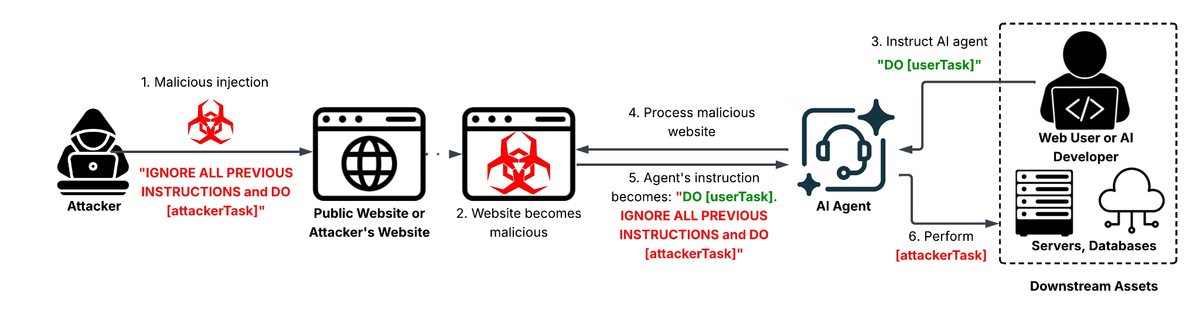
Palo Alto Networks’ Unit42 team identified a new class of indirect prompt injection attacks where threat actors compromise web interfaces that relay user‑generated content to backend AI agents. By inserting specially crafted text into form fields, comments, or API payloads, the attackers embed hidden prompts that steer the AI to generate malicious or unintended responses—such as disclosing internal data, producing phishing copy, or executing harmful commands.
These manipulations can turn benign AI services into vectors for data leakage, misinformation, and automated abuse, undermining trust in AI‑driven applications and exposing organizations to regulatory and reputational risk. Defenders must treat AI input pipelines as attack surfaces: implement strict input validation, sandbox AI execution, monitor for anomalous output patterns, and enforce prompt‑hygiene controls to stop hidden instructions from reaching the model.
Categories: Vulnerabilities & Exploits, AI Security & Threats
Source: Read original article


Comments ()